Was eigentlich ist Unicode?
Der Großteil unserer Kommunikation basiert auf der Sprache und der Schrift, wobei sich im Laufe der Zeit eine unglaubliche Vielfältigkeit entwickelt hat. Um diese Vielfältigkeit in den Griff zu bekommen, wurde Unicode entwickelt.Die Unicode-Spezifikation
 Der Großteil unserer Kommunikation basiert auf unserer Sprache und unserer Schrift, wobei sich im Laufe der Zeit eine unglaubliche Vielfältigkeit entwickelt hat.
Der Großteil unserer Kommunikation basiert auf unserer Sprache und unserer Schrift, wobei sich im Laufe der Zeit eine unglaubliche Vielfältigkeit entwickelt hat.
Um diese Vielfältigkeit im Bereich der elektronischen Datenverarbeitung in den Griff zu bekommen, wurde Unicode entwickelt. Unicode ist heute die am häufigsten verwendete Zeichenkodierung im Internet und setzt sich flächendeckend immer mehr durch.
Unicode ist zunächst einmal nur eine Spezifikation, die jedem Zeichen auf der Welt eine eindeutige Nummer zuordnet. Kommen neue Zeichen hinzu, so sorgt die Unicode-Spezifikation dafür, dass diese neuen Zeichen ebenfalls eine Nummer erhalten.
Zur Zeit sieht die Unicode-Spezifikation 17 Ebenen vor, wobei jede Ebene 65.536 Zeichen - so genannte Codepoints - enthalten kann. Jede Ebene wird dabei in Blöcke unterteilt, die immer ein Vielfaches von 16 sein müssen. Daher gibt es auch Bereiche in den Ebenen, die keine Zeichen enthalten.
Gerne wird zur Darstellung die hexadezimale Schreibweise verwendet. Das heisst, die erste Ebene belegt den Bereich 0000 bis FFFF, die zweite Ebene den Bereich 10000 bis 1FFFF und die letzte Ebene den Bereich 100000 bis 10FFFF. Und wenn keine Lücken zugelassen wären, könnten in den 17 Ebenen insgesamt 65.536 * 17 = 1.114.112 ( = 10FFFF) Zeichen gespeichert werden.
Die Aufteilung der Ebenen:
- Plane 0 (0000–FFFF): Basic Multilingual Plane (BMP)
- Plane 1 (10000–1FFFF): Supplementary Multilingual Plane (SMP)
- Plane 2 (20000–2FFFF): Supplementary Ideographic Plane (SIP)
- Planes 3 to 13 (30000–DFFFF): Unbelegt
- Plane 14 (E0000–EFFFF): Supplementary Special-purpose Plane (SSP)
- Plane 15 (F0000–FFFFF): Private Use Area (PUA)
- Plane 16 (100000–10FFFF): Private Use Area (PUA)
Die erste Ebene wird Basic Multilingual Plane (BMP) oder auch nur Ebene 0 genannt und enthält zum großen Teil Zeichen von Schriftsystemen, die aktuell in Gebrauch sind, entsprechende Satzzeichen, Symbole und Kontrollzeichen sowie einen Bereich für die private Nutzung. Die ersten 128 Zeichen der BMP entsprechen dem ASCII-Zeichensatz bzw. die ersten 256 Zeichen dem ISO Latin-1 (ISO 8859-1) Standard, der die meisten Zeichen der west-europäischen Sprachen zusammenfasst.
So ist zum Beispiel der Buchstabe a in der BMP an Position 97 zu finden. In hexadezimaler Schreibweise entspricht dies dem Wert 0061 und damit dem Codepoint U+0061, wobei das U+ angibt, dass es sich bei dieser Darstellung um einen Codepoint handelt.
Die BMP ist aus historischen Gründen stark fragmentiert und größtenteils belegt, so dass umfangreichere Schriftsysteme nicht mehr Platz finden und auf andere Ebenen ausgelagert werden. Dazu gehören zum Beispiel historische Schriftzeichen, alt-ägyptische Hieroglyphen oder kaum noch gebräuchliche chinesisches Schriftzeichen usw.
Beispiele:
Buchstabe a: Ebene 0 (BMP), Codepoint U+0061 (dezimal 97)
Buchstabe ä: Ebene 0 (BMP), Codepoint U+00E4 (dezimal 228)
Notenschlüssel: Ebene 1, Codepoint U+1D11E (dezimal 119070 = Position 53534 in Ebene 1)
Kodierungsformate für Unicode Zeichen
Zur Darstellung der Unicode-Zeichen auf einem Computer wurden verschiedene Kodierungsformate definiert. Zu den bekanntesten zählen UTF-8, UTF-16, UTF-32 sowie UCS-2 und UCS-4. Eine Kodierung ist dabei eine Vorschrift, die beschreibt, wie die Unicode-Zeichen auf Folgen von Bytes abgebildet werden. Die verschiedenen Formate unterscheiden sich hinsichtlich Platzbedarf, dem Kodierungs- und Dekodierungsaufwand sowie in ihrer Kompatibilität zu anderen (älteren) Kodierungsarten, wie zum Beispiel ASCII oder Latin-1.
Zeichenkodierungen, bei denen Zeichen mit einer fixen Anzahl von Bits bzw. Bytes kodiert werden, sind zum Beispiel:
- ASCII: 7 Bit Code: 128 Zeichen
- Latin-1: 8 Bit Code: 256 Zeichen (auch als ISO 8859-1 bzw. ANSI bekannt)
- UCS-2: 16 Bit Code: 65536 Zeichen
- UCS-4: 32 Bit Code: 4294967296 Zeichen
- UTF-32: 32 Bit Code: 4294967296 Zeichen (kein Unterschied zu UCS-4)
Die folgende Liste zeigt, wie die entsprechenden Anzahlen berechnet werden:
- 1 Bit: 21 = 2 Zustände (Binär: 0 bis 1, Dezimal: 0 bis 1, Hexadezimal: 0 bis 1)
- 7 Bit: 27 = 128 Zustände (Binär: 0 bis 1111111, Dezimal: 0 bis 127, Hexadezimal: 0 bis 7F)
- 1 Byte: 28 = 256 Zustände (Binär: 0 bis 11111111, Dezimal: 0 bis 255, Hexadezimal: 0 bis FF)
- 2 Byte: 216 = 65536 Zustände (Dezimal: 0 bis 65535, Hexadezimal: 0 bis FFFF)
- 4 Byte: 232 = 4294967296 Zustände (Dezimal: 0 bis 4294967295, Hexadezimal: 0 bis FFFFFFFF)
UTF-8 und UTF-16 verwenden - im Gegensatz zu oben aufgeführten Zeichenkodierungen - eine variable Anzahl von Bytes, um Zeichen zu kodieren. Die entsprechenden Verfahren sind weiter unten detailliert beschrieben.
ASCII und Latin-1
Latin-1 ist ein von der ISO zuletzt 1998 aktualisierter Standard zur Zeichenkodierung mit acht Bit. Er stellt den ersten Teil Normenfamilie ISO/IEC 8859 dar und wird unter dem Namen westeuropäischer Zeichensatz geführt. Insgesamt definiert diese ISO-Norm 16 Zeichensätze:
Latin-1 (Westeuropäisch), Latin-2 (Mitteleuropäisch), Latin-3 (Südeuropäisch), Latin-4 (Nordeuropäisch), Kyrillisch, Arabisch, Griechisch, Hebräisch, Latin-5 (Türkisch), Latin-6 (Nordisch), Thai, Latin-7 (Baltisch), Latin-8 (Keltisch), Latin-9 (Westeuropäisch) und Latin-10 (Südosteuropäisch).
Die ersten 128 Zeichen (also alle Zeichen, die mit 7 Bit kodiert werden) sind bei allen diesen Zeichensätzen gleich und entsprechen den Zeichen ASCII Zeichensatzes.
Der häufig benutzte Latin-1-Zeichensatz ist identisch mit den ersten 256 Zeichen des Unicode-Zeichensatzes. Das folgende Tabelle zeigt, welche Bereiche belegt und welche Zeichen in Latin-1 definiert sind.
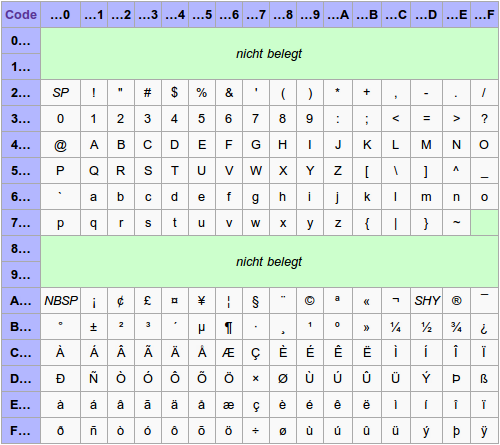
Latin-1 Zeichensatz
ISO 8859-1 ist neben ASCII und UTF-8 die wohl wichtigste und am häufigsten gebrauchte Kodierung und reicht für mindestens folgende Sprachen aus:
UCS-2
UCS-2 (2-Byte Universal Character Set) ist ein Kodierungsformat für Unicode-Zeichen, das für die Basic Multilingual Plane optimiert ist. Dabei findet bei der Kodierung eine 1:1 Abbildung zwischen den Unicode-Zeichen der BMP und den entsprechenden Byte-Folgen statt. Das heisst, dass die Unicode-Zeichen direkt auf die 16 Bits einer 2-Byte-Folge abgebildet werden.
Beispiel:
Buchstabe a: Codepoint U+0061 (dezimal 97) -> binär 00000000 01100001
Buchstabe ä: Codepoint U+00E4 (dezimal 228) -> binär 00000000 11100100
Grad-Celsius-Zeichen ℃: Codepoint U+2103 (dezimal 8451) -> binär 00100001 00000011
Wird nun ein Codepoint übertragen oder gespeichert, so ist nicht definiert, welches Byte zuerst übertragen werden muss. Deshalb spricht man von UCS-16BE (UCS-16 Big Endian) bzw. UCS-16LE (UCS-16 Little Endian) je nachdem, welches der beiden Bytes zuerst übertragen bzw. gespeichert wird. Auf diese Problematik wird weiter unten noch näher eingegangen.
Und wie die dezimale Zahlendarstellung mit der binären bzw. hexadezimalen Darstellung zusammenhängt, verdeutlichen die folgenden Berechnungen:
228 = 1 * 264 + 1 * 232 + 1 * 216 + 0 * 28 + 0 * 24 + 1 * 22 + 0 * 21 + 0 * 20 = 11100100 (binär)
228 = 0 * 163 + 0 * 162 + 14 * 161 + 4 * 160 = 0 0 14 4 = 00E4 (hexadezimal)
Bemerkung: Im hexadezimalen System werden die Zahlen 10 bis 15 durch die Buchstaben A bis F dargestellt.
UCS-4 und UTF-32
UCS-4 und UTF-32 sind identische Zeichensätze. Sie bilden die Unicode-Zeichen auf die Byte-Folgen genau so ab wie UCS-2, nur dass hier 32 Bit anstatt 16 Bit verwendet werden. Damit kann UCS-4 bzw. UTF-32 alle Unicode-Zeichen 1:1 abbilden. Da außerdem keine variablen Bytelängen wie z.B. bei UTF-16 verwendet werden, ist sie die einfachste aller Unicode-Kodierungen. Der entscheidende Nachteil von UCS-4 bzw. UTF-32 ist natürlich der hohe Speicherbedarf. Bei Texten, die überwiegend aus lateinischen Buchstaben bestehen, wird - im Vergleich mit der verbreiteten UTF-8 Kodierung - etwa der vierfache Speicherplatz belegt.
UTF-16
Da mit UCS-2 nur die Unicode-Zeichen aus der Basic Multilingual Plane kodiert werden können, wurde bei UTF-16 etwas getrickts, um Zeichen darzustellen, die außerhalb der BMP liegen. UTF-16 repräsentiert zunächst alle Codepoints von U+0000 bis U+FFFF als 16-bit Folge. Für die Darstellung von Codepoints, die größer als U+FFFF sind, werden aber 32 Bit benötigt. Deshalb wurde festgelegt, dass in den Codebereichen der BMP von U+D800 bis U+DBFF und von U+DC00 bis U+DFFF keine 16-bittigen Darstellungen gespeichert werden, sondern der Platz für UTF-16 Ersatzzeichen reserviert bleibt. Eine Anleitung, wie die entsprechenden Codepoints dann in Bit-Folgen umgerechnet werden, findet sich im entsprechenden UTF-16-Artikel in der Wikipedia.
Bei UTF-16 wird also jedes Zeichen in Form von 2 bzw. 4 Bytes dargestellt. Der Vorteil von UTF-16 ist, dass die Bytelänge eines Zeichens genau definiert ist. Der große Nachteil ist aber, dass bei fest definierten Bytelängen immer nur eine begrenzte Anzahl von Zeichen codiert werden können bzw. dass zur Darstellung immer mindestens 2 Bytes erforderlich sind.
UTF-8
Um diesen Nachteil auszugleichen wurde UTF-8 entwickelt. UTF-8 verwendet für häufig vorkommende Zeichen - wie zum Beispiel für ASCII- und Latin-1-Zeichen - einzelne Bytes. Alle anderen Zeichen werden über eine Art "Escapesequenz" definiert, d.h. das erste Byte ist eine Art Code, der festlegt, wie die nachfolgenden Bytes interpretiert werden. So wird zum Beispiel für das Abspeichern des Zeichens "a" nur ein Byte benötigt, während für das Grad-Celsius-Zeichen "℃" bereits 2 Bytes erforderlich sind. Durch seine Flexibilität ist UTF-8 im Internet in der Zwischenzeit zum Quasi-Standard geworden und wird bei HTML-Dokumenten immer öfter als bevorzugter Zeichensatz verwendet.
UTF-8 ist eine verlustlose Zeichenkodierung, die Bit-Darstellungen in unterschiedlicher Längen von einem bis vier Bytes verwendet. Das Schema dabei ist ziemlich einfach:
Codepoints in UTF-8 für die Bit-Darstellungen unterschiedlicher Länge:
- Codepoints 000000 – 00007F ---> 0xxxxxxx
- Codepoints 000080 – 0007FF ---> 110xxxxx 10xxxxxx
- Codepoints 000800 – 00FFFF ---> 1110xxxx 10xxxxxx 10xxxxxx
- Codepoints 010000 – 10FFFF ---> 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Die x stehen dabei für die binäre Darstellung eines Codepoints. Die Anzahl der Einsen zu Beginn eines Blocks geben die Länge der Darstellung an. Die Bytes, die ebenfalls noch zur Darstellung gehören, beginnen mit 10.
Um jetzt einen Codepoint in seine UTF-8-Darstellung umzuwandeln, geht man wie folgt vor:
- Angenommen, der Codepoint ist U+00E4. Binär wird 00E4 als 1110 0100 dargestellt.
- 00E4 liegt im Bereich 000080 – 0007FF, d.h. es werden zwei Bytes für die Darstellung benötigt.
- Jetzt werden die x von hinten nach vorne mit der binären Darstellung ersetzt und gegebenenfalls vorne mit Nullen aufgefüllt: 11000011 10100100 (hexadezimal: C3A4).
- Der Codepoint U+00E4 entspricht also dem Wert 0xC3A4 in der UTF-8-Kodierung.
Byte-Order-Mark
Bei unzureichend spezifizierten Protokollen - also wenn die Angabe fehlt, ob die Bytes in der Little- oder Big-Endian Form gespeichert wurden - wird empfohlen, an den Anfang einer jeden Unicode-Datei die Byte-Order-Mark (BOM) hinzuzufügen, damit jedes Unicode-fähige Programm beim Einlesen einer Datei erkennen kann, welches Kordierungsformat benutzt wurde. Bei UTF-8 stellt sich das Problem der Byte-Reihenfolge zwar nicht, doch eine Byte-Order-Mark ist erlaubt, um die Verwendung von UTF-8 als Kodierung zu kennzeichnen. Folgende Markierungen sind für BOM's gebräuchlich:
- 00 00 FE FF steht für "UTF-32, Big Endian"
- FF FE 00 00 steht für "UTF-32, Little Endian"
- FE FF steht für "UTF-16, Big Endian"
- FF FE steht für "UTF-16, Little Endian"
- EF BB BF steht für "UTF-8"


Sicheres Passwort erstellen
Moderne Kommunikation erfordert höchste Sicherheitsstandards
Ip basierter Anschluss - was steckt dahinter?
Die Deutsche Telekom bietet nur noch ip basierte Anschlüsse an. Top oder Flop?

