Python und Unicode
Unicode ist erstmal nur eine Spezifikation, die jedem Zeichen auf der Welt eine eindeutige Nummer vergibt.Wie unterschiedlich Zeichen dargestellt und kodiert werden können, zeigen die folgenden Repräsentationen des Buchstabens »ä«:
- Das Zeichen 'ä' als Codepoint in Unicode: U+00E4 (Dezimal: 228)
- Das Zeichen 'ä' als Ausgabestring von Python: \xe4 (Dezimal: 228)
- Das Zeichen 'ä' als Latin1 Zeichen: 0xE4 (Dezimal: 228)
- Das Zeichen 'ä' als UTF-8 Zeichen: 0xC3A4 (Dezimal: 50084)
- Das Zeichen 'ä' in HTML als Zeichenreferenz: ä
- Das Zeichen 'ä' in HTML als Dezimalreferenz: ä (Dezimal: 228)
- Das Zeichen 'ä' in HTML als Hexadezimalreferenz: ä (Dezimal: 228)
- Das Zeichen 'ä' in einer URL in Latin1 Encoding: %E4 (Dezimal: 228)
- Das Zeichen 'ä' in einer URL in UTF-8 Encoding: %C3%A4 (Dezimal: 50084)
Werden die verschiedenen Darstellungen durchmischt, kann es vorkommen, dass Zeichen nicht mehr korrekt dargestellt werden. Die fehlerhafte Darstellung des Buchstabens »ä« durch die Zeichenfolge »Ã¤« resultiert zum Beispiel daraus, dass anstelle des UTF-8 kodierten Zeichens »ä« (C3A4) die beiden Latin-1 Zeichen »Ã« (C3) und »¤« (A4) verwendet werden.
Wie die Ausgaben mit den Einstellungen des Terminals und anderen Encoding-Möglichkeiten zusammenhängen, wird in den folgenden Abschnitten beschrieben. Auf jeden Fall können im interaktiven Modus von Python die Bytecodierungen von Strings direkt ausgegeben werden:
>>> unicode( 'ä', 'UTF-8') u'\xe4' >>> unicode( 'ä', 'Latin-1') u'\xc3\xa4'
Verarbeitung von Zeichenketten in Python
Die Verarbeitung von Zeichenketten erfolgt in Python mit Hilfe der sequenziellen Datentypen str und unicode, wobei ihr Einsatz vom jeweiligen Anwendungsfall abhängt. Beide String-Klassen haben eine weitgehend identische API und sind von der abstrakten Basisklasse basestring abgeleitet.
Der interaktive Modus
Achtung: Um die Beispiele nachvollziehen zu können, sollte das Terminal beim interaktiven Modus auf Latin-1 gestellt werden und das Default-Encoding von Python auf ASCII gesetzt sein. Wie das Encoding für ein Terminal unter Linux geändert wird, zeigt die Abbildung auf der rechten Seite (Ubuntu).
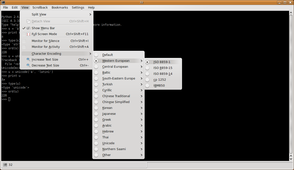
Encoding Einstellung im Terminal
Das Default-Encoding für Python kann unter Linux in der Datei sitecustomize.py eingestellt werden, wobei diese Datei zum Beispiel im Verzeichnis /usr/lib/python2.6/ oder /etc/python2.6/ zu finden ist. In der Regel ist das Default-Encoding bereits auf ASCII gesetzt, kann aber auch mit den Zeilen import sys und sys.setdefaultencoding('ascii') geändert werden. Im interaktiven Modus wird das aktuelle Default-Encoding mit dem Befehl sys.getdefaultencoding() abgefragt.
Zusätzlich gibt es noch eine Encoding-Einstellung für den print-Befehl. Dieses Encoding kann mit dem Befehl sys.stdout.encoding abgefragt werden und ist in den folgenden Beispielen auf UTF-8 gesetzt (default Wert).
Die beiden Code-Beispiele zeigen, wie unterschiedlich die Ausgaben bei verschiedenen Terminal-Einstellungen sein können. Das Default-Encoding für Python ist in beiden Beispielen auf ASCII gesetzt, das Encoding für den print-Befehl auf UTF-8.
# Terminal-Einstellung Latin-1 >>> import sys >>> sys.getdefaultencoding() 'ascii' >>> sys.stdout.encoding 'UTF-8' >>> s = 'Sägesp\xe4ne' >>> s 'S\xe4gesp\xe4ne' >>> type(s) >>> print s Sägespäne >>> u = u'Sägesp\xe4ne' >>> u u'S\xe4gesp\xe4ne' >>> type(u) >>> print u Sägespäne
# Terminal-Einstellung UTF-8 >>> import sys >>> sys.getdefaultencoding() 'ascii' >>> sys.stdout.encoding 'UTF-8' >>> s = 'Sägesp\xe4ne' >>> s 'S\xc3\xa4gesp\xe4ne' >>> type(s) >>> print s Sägesp�ne >>> u = u'Sägesp\xe4ne' >>> u u'S\xe4gesp\xe4ne' >>> type(u) >>> print (u) Sägespäne
Bytestrings
Zeichenketten werden bei Instanzen des Typs str als Folgen von Bytes gespeichert und eignen sich daher besonders gut für binäre Datenströme. Da bei Bytestrings jeweils ein Byte einem Zeichen zugeordnet wird, können mit Bytestrings maximal 256 verschiedene Zeichen kodiert werden.
Welcher Bytewert nun welches Zeichen darstellt, hängt von der zugrunde liegenden Kodierung ab. Oft entsprechen die ersten 128 Bytewerte dem ASCII-Zeichensatz, wie dies unter anderem bei den Kodierungen Latin-1, Latin-7 und UTF-8 der Fall ist. So werden in Latin-1 (Westeuropäisch) die Bytewerte 72, 228, 116, 116 und 101 auf den String 'Hätte' abgebildet. In der Kodierung Latin-7 (Griechisch) ergibt dies den String 'Hδtte': Alle Zeichen - abgesehen vom Umlaut 'ä', der einen Bytewert größer als 128 aufweist - sind in beiden Kodierungen identisch. Wer Genaueres hierzu erfahren möchte, liest sich am Besten den Wikipedia-Artikel ISO 8859 durch: Der Bytewert 228 entspricht in Latin-1 dem deutschen Buchstaben 'ä' und in Latin-7 dem griechischen Buchstaben Delta δ.
Um den Zahlenwert eines Zeichens zu bestimmen, kann in Python die Funktion ord() verwendet werden. Der einzige Parameter ist genau ein Zeichen - also einen String der Länge eins. Auf der anderen Seite gibt es die Funktion chr(), die das einem Bytewert entsprechende Zeichen liefert. Die Länge eines String kann mit der Funktion len() ermittelt werden.
Auf einem Linux-Rechner, der die Zeichentabelle »Latin-1« verwendet, wird ord('ä') den Wert 228 liefern und umgekehrt chr(228) den Buchstaben 'ä'. Auf anderen Rechnern, die mit anderen Codepages arbeiten, kann die Ausgabe völlig anders ausfallen. So wird zum Beispiel auf einem Rechner mit UTF-8 Kodierung bei Eingabe von chr(228) der String '\xe4' ausgegeben. Der Befehl ord('ä') hingegen liefert einen Fehler, da bei der UTF-8 Kodierung das Zeichen 'ä' aus 2 Bytes besteht und damit als 2 Zeichen interpretiert wird.
Beim Umgang mit Bytestrings ist es deshalb immer wichtig, die zugrunde liegende Kodierung zu beachten. Die folgenden Beispiele zeigen auf der linken Seite die Terminalausgaben im interaktiven Modus unter Latin-1 Kodierung, auf der rechten Seite die Terminalausgaben unter UTF-8 Kodierung.
>>> s = 'ä' >>> len(s) 1 >>> ord(s) 228 >>> type(s) >>>
>>> s = 'ä' >>> len(s) 2 >>> ord(s) Traceback (most recent call last): File "", line 1, in TypeError: ord() expected a character, but string of length 2 found
Binäre Strings
Binäre Strings eigenen sich schlecht zum Versenden in E-Mails, als Teil einer URL oder für einen HTTP Post Request. Das Modul base64 definiert die Base16, Base32 und Base64 Algorithmen, um binäre Strings in Text Strings zu verwandeln und umgekehrt. Das linke Code-Snippet zeigt ein Beispiel, wie ein binärer String erzeugt, in einen Text-String konvertiert und wieder zurück konvertiert wird. Ein URL-Sichere String-Konvertierung zeigt das rechte Snippet.
import base64, random binary_text = ''.join(chr(random.randint(0, 0xFF)) for i in range(16)) print binary_text A�Dz�(e��!�9��a print base64.b64encode(binary_text) QbNEHHqIKGWH3iH7OcneYQ== print base64.b64decode(base64.b64encode(binary_text)) A�Dz�(e��!�9��a
import base64 test = "Hi, I'm a string" enc = base64.urlsafe_b64encode(test) enc 'SGksIEknbSBhIHN0cmluZw==' uenc = unicode(enc) base64.urlsafe_b64decode(enc) "Hi, I'm a string" base64.urlsafe_b64decode(uenc) ... TypeError: character mapping must return integer, None or unicode base64.urlsafe_b64decode(uenc.encode("utf-8")) "Hi, I'm a string"Unicode-Strings
Der Datentyp unicode ist für die Verarbeitung von Texten, die Sonderzeichen - wie zum Beispiel deutsche Umlaute oder das Eurozeichen enthalten - ausgelegt und speichert Folgen von Zeichen als sogenannte Unicode-Codepoints ab. Was genau ein Codepoint ist, beschreibt der Artikel "Was eigentlich ist Unicode?".
Ein Unicode-String kann entweder mit der unicode()-Funktion oder durch ein String-Literal, dem der Buchstabe 'u' vorangestellt wird, erzeugt werden. Bei der unicode()-Funktion wird die Default-Encodierung verwendet - standardmäßig also die ASCII Kodierung. Das heißt der Aufruf von unicode('ä') führt zu einem Fehler, da das 'ä' nicht im ASCII-Zeichensatz vorhanden ist. Bei der unicode()-Funktion kann aber die Kodierung angegeben werden, d.h. ein Aufruf in der Form unicode('ä', 'latin1') funktioniert.
Damit Unicode-Strings genau so aussehen wie normale Bytestrings, werden innerhalb von Unicode-Strings alle Sonderzeichen mit Bytewerten im Bereich von 128 bis 255 durch Escape-Sequenzen, denen ein "\x" vorangestellt ist, dargestellt. Eine Escape-Sequenz, der ein "\u" vorangestellt wird, dient dazu, um einen beliebigen Codepoint direkt mit seinem Zahlenwert anzugeben. So kann zum Beispiel das Eurozeichen »€« mit der Codepoint-Sequenz »U+20ac« dargestellt werden.
Im interaktiven Modus wird dies deutlich, wenn man einen Unicode-String ohne print ausgibt. Denn dann wird für die Unicode-Instanzen ein Literal erzeugt, in dem alle Sonderzeichen als Escape-Sequenzen kodiert sind. Dies hat zur Folge, dass für das Literal nur ASCII-Zeichen verwendet werden.
Die folgenden Beispiele wurden in einem Terminal mit Latin-1 Kodierung und der Default-Encodierung ASCII durchgeführt.
>>> u1 = u'ä' >>> u1 u'\xe4' >>> print u1 ä >>> type(u1) >>> len(u1) 1 >>> u2 = unicode('ä') Traceback (most recent call last): File "", line 1, in UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128) >>> u3 = unicode('ä', 'latin1') >>> u3 u'\xe4' >>> u4 = u'H\xe4tte ich nur 10 \u20ac gehabt, dann hätte ich den Bus nehmen können.' >>> u4 u'H\xe4tte ich nur 10 \u20ac gehabt, dann h\xe4tte ich den Bus nehmen k\xf6nnen.' >>> print u4 Hätte ich nur 10 ⬠gehabt, dann hätte ich den Bus nehmen können.Erklärungen
Im ersten Beispiel wird ein Unicode-String erzeugt, der den Buchstaben 'ä' enthält. Dass es sich dabei um einen Unicode-String handelt, wird bei der Ausgabe des Strings u1 deutlich: Dem Literal ist ein u vorangestellt und der Codepoint e4 entspricht dem Unicode-Zeichen 'ä'. Da Python bei der Ausgabe mit print auf das Default-Encodierung von stdout - also UTF-8 - zurückgreift, das Terminal aber auf Latin-1 eingestellt ist, wird das Zeichen 'ä' in der Form 'ä' ausgegeben.
Im zweiten Beispiel wird versucht, mit dem unicode()-Konstruktor dem String u2 das Zeichen 'ä' mit der Default-Encodierung - also ASCII - zuzuweisen. Dies führt natürlich zu einem Fehler, da das 'ä' in ASCII nicht enthalten ist.
Wird hingegen die richtige Kodierung verwendet - wie im Beispiel 3 gezeigt - funktioniert die Zuweisung problemlos.
Im letzten Beispiel wird ein Unicode-String erzeugt, der Umlaute und verschiedene Escape-Sequenzen enthält. Bei der print Anweisung wird - wie in Beispiel 1 - wieder auf die Default-Encodierung von stdout zurückgegriffen, d.h. zur Ausgabe wird UTF-8 verwendet, das Terminal zeigt aber Latin-1 Zeichen an.
Zusammenfassung
Bei der Verarbeitung und Ausgabe von Bytestrings und Unicode-Strings sind im interaktiven Modus folgenden Dinge zu beachten:
- Auf welche Kodierung ist das Ausgabe-Terminal eingestellt? -> Latin-1
- Auf welche Kodierung ist das Default-Encoding von Python eingestellt (sys.getdefaultencoding) -> ASCII
- Auf welche Kodierung ist Python's stdout eingestellt (sys.stdout.encoding) -> UTF-8
Was sind die Unterschiede zwischen Bytestrings und Unicode-Strings
- Bytestrings bestehen aus einer Folge von Bytes und können maximal 256 Zeichen darstellen
- Unicode-Strings bestehen aus einer Folge von Codepoints. Theoretisch sind damit über 4 Billionen Zeichen darstellbar
Zu dieser Thematik gibt es eine hervorragende englische Seite, die auf jeden Fall einen Blick wert ist:
Verarbeitung von Datenströmen
Unicode-Strings sind bestens für die Arbeit mit Texten, die Sonderzeichen enthalten, geeignet und erleichtern so den Umgang mit internationalen Schriftzeichen. Wie wir in den vorhergehenden Abschnitten gelernt haben, abstrahieren Unicode-Strings von Bytes auf Zeichen bzw. Codepoints. Dies hat für den Programmiere viele Vorteile, doch eine Maschine kann damit nicht viel anfangen, da diese mit Byte-Folgen arbeiten. Gerade beim Speichern von Daten auf ein Speichermedium, beim Austausch von Daten mit anderen Programmen oder wenn Daten versendet werden ist der Rechner auf diese Byte-Ketten angewiesen. Daher müssen Möglichkeiten geschaffen werden, um aus abstrakten Unicode-Strings konkrete Byte-Folge zu erzeugen und umgekehrt.
Python bietet hierzu die Methoden encode() und decode() an. Die Methode encode() ist eine Methode von einer Unicode-Instanz, der als Parameter der Name der gewünschten Kodierung übergeben wird. Als Ergebnis erhält man eine String-Instanz, die den String in der übergebenen Kodierung enthält. Umgekehrt macht die Methode decode() aus einer kodierten String-Instanz wieder ein Unicode-Objekt.
Nach Möglichkeit sollte man sich bei der Verarbeitung von Datenströmen an die folgende Regel halten: So früh wie möglich Dekodieren, so spät wie möglich Enkodieren.
Beispiele zum Dekodieren
>>> s = 'a' >>> type(s) >>> u = s.decode('ascii') >>> type(u) >>> s = 'ä' >>> type(s) >>> u = s.decode('ascii') Traceback (most recent call last): File "", line 1, in UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128) >>> u = s.decode('latin-1') >>> type(u) Beispiele zum Encodieren
>>> s = u'a'.encode() >>> type(s) >>> print s a >>> s = u'ä'.encode() Traceback (most recent call last): File "", line 1, in UnicodeEncodeError: 'ascii' codec can't encode character u'\xe4' in position 0: ordinal not in range(128) >>> s = u'ä'.encode('latin-1') >>> type(s) >>> print s ä >>>Machen die Umkehrungen Sinn?
Was passiert nun, wenn man Unicode-Strings dekodiert bzw. Bytestrings encodiert - also genau den umgekehrten Weg geht? Letztendlich gibt es ein wohl paar Spezialfälle, wo dies Sinn macht. So kann man zum Beispiel die decode()-Methode auf Unicode-Strings anwenden, um Nicht-Charakter-Encodings zu handhaben. Wie auch immer, in Python 3 fallen diese Methoden einfach weg... Und das ist ja die Zukunft :-)
Fehlerbehebung beim Dekodieren und Enkodieren
Beim En- und Dekodieren kann - wie wir gesehen haben - einiges schiefgehen. So enthält der ASCII-Code ja z.B. keine deutschen Umlaute. Eine Enkodierung des Zeichens 'ä' mit dem ASCII-Encoding führt also zu einem Fehler. In der Regel benötigt man in solchen Fällen eine Fehleranalyse bzw. Fehlerbehebung.
In Situationen, in denen dies aber nicht machbar oder gar nicht erwünscht ist, kann man der encode()-Methode zusätzlich den Parameter "ignore" oder "replace" übergeben, damit das nicht enkodierbare Zeichen ignoriert oder ersetzt wird.
>>> u'Hätte'.encode('ascii') Traceback (most recent call last): File "", line 1, in UnicodeEncodeError: 'ascii' codec can't encode character u'\xe4' in position 1: ordinal not in range(128) >>> u'Hätte'.encode('ascii', 'ignore') 'Htte' >>> u'Hätte'.encode('ascii', 'replace') 'H?tte'HTML-Entities und URL-Encodings
Nun ist es aber so, dass in der Welt der Computer nicht nur zwischen normalen Strings und Unicode-Strings unterschieden wird. Wer sich schon einmal mit HTML beschäftigt hat, kennt sicher die numerischen Zeichenreferenzen. Diese beginnen entweder mit dem "&"-Zeichen bzw. dem "#"-Zeichen, denen dann in dezimaler bzw. hexadezimaler Schreibweise die Zeichenposition des Zeichens im Unicode-Zeichensatz sowie ein abschließender Semikolon folgt.
Daneben gibt es dann noch die benannten Zeichenreferenzen (auch Entity-Zeichenreferenzen oder Zeichenentitäten genannt) wie zum Beispiel die Referenz um das Non-Breakable-Space darzustellen.
Um in URL's bestimmte Zeichen darzustellen, wurde die URL-Kodierung - auch Prozentkodierung genannt - eingeführt. Dies ist ein Mechanismus, um Informationen in einer URL unter bestimmten Gegebenheiten zu kodieren. Zur Kodierung sind nur bestimmte Zeichen des ASCII-Zeichensatzes zugelassen.
Ohne diese Kodierung wären einige Informationen wie z.B. Leerzeichen in einer URL nicht darstellbar. Für das Leerzeichen wird die URL-Kodierung %20 verwendet, d.h. die Kodierung ist eine 3-stellige Zeichenkombination, die mit dem Prozentzeichen eingeleitet wird und dem die zweistellige hexadezimale Darstellung des Zeichencodes folgt.
Leider gibt es noch keinen Standard, der vorschreibt, in welchem Format die Kodierung zu erfolgen hat. In der Regel wird aber für die Prozentkodierung von URL's die UTF-8 Kodierung verwendet. In diesem Fall würde der Buchstaben "ä" dann mit der Zeichenfolge %C3%A4 kodiert.
HTML-Entities escapen
Da Python in der Version 2.6 (bzw. darunter) von sich aus keine Möglichkeit anbietet, HTML-Entities zu escapen, hilft eventuell das folgenden Codebeispiel weiter, das das Escapen nachbildet.
# Escaping HTML escaping = { '&': '&, ', "'": '&apos, ', '"': '"', '': ">", } def escape(string): return ''.join(escaping.get(s,s) for s in string) # Unescaping HTML def unescape(s): s = s.replace('<', '') # Dies muss zum Schluss erfolgen s = s.replace('&', '&') return s # Der HTML-Parser unterstützt selber einige Entities import htmllib def unescape(s): p = htmllib.HTMLParser(None) p.save_bgn() p.feed(s) return p.save_end()URL's encoden
Dafür gibt es in Python verschiedene Möglichkeiten, eine URL zu Kodieren bzw. Encodieren. Die entsprechenden Funktionen stellt die urllib zur Verfügung:
- urllib.quote(): Ersetzt spezielle Zeichen in Strings durch die %xx Sequenz. Buchstaben, Zahlen und die Zeichen "_,. -" werden nie quotiert.
- urllib.quote_plus(): Macht das gleiche wie urllib.quote, nur dass zusätzlich Leerzeichen durch ein Plus-Symbol ersetzt werden.
- urllib.parse.quote_from_bytes(): Macht das gleiche wie urllib.quote, aber akzeptiert ein Byte-Objekt im Gegensatz zu einem String (erst ab Python Version 3.0).
Dazu gibt es dann noch die entsprechenden Umkehrungen:
- urllib.unquote(): Die Funktion urllib.unquote ist das Gegenstück von quote. Escape-Sequenzen der Form %xx werden durch das Sonderzeichen ersetzt, und der resultierende String wird zurückgegeben.
- urllib.unquote_plus(): Macht das gleiche wie urllib.unquote, nur dass zusätzlich Plus-Symbole durch Leerzeichen ersetzt werden.
- urllib.parse.unquote_to_bytes(): Macht das gleiche wie urllib.unquote, aber akzeptiert ein Byte-Objekt im Gegensatz zu einem String (erst ab Python Version 3.0).
>>> import urllib >>> urllib.quote('Alles kann man ändern') 'Alles%20kann%20man%20%C3%A4ndern' >>> urllib.quote_plus('Alles kann man ändern') 'Alles+kann+man+%C3%A4ndern' # Ab Python Version 3.0 >>> urllib.quote_from_bytes(b'a&\xef') 'a%26%EF' 

Verzerrte Intelligenz: Warum KI nicht objektiv ist
KI wirkt neutral, doch systematische Verzerrungen zeigen viele Gesichter. Ein Überblick über Ursachen und Folgen von Bias.
Bias erkennen und mindern: Werkzeuge für faire KI
Bias sind systematische Verzerrung bei der Anwendung von Künstlicher Intelligenz. Seine Auswirkungen können bei Menschen Wut auslösen. Wie können wir Bias ...

